Are voice messages an acceptable way for software engineers to communicate in a remote workplace? Some of the key features of AWS Glue include: To know more about AWS Glue, visit this link. Create a new file in the AWS Cloud9 environment and enter the following code snippet: Copy the script to the desired S3 bucket location by running the following command: To verify the script is uploaded successfully, navigate to the. What exactly is field strength renormalization? You can entrust us with your data transfer process and enjoy a hassle-free experience. Your cataloged data is immediately searchable, can be queried, and is available for ETL. Learn more about BMC . You can find the function on the Lambda console. 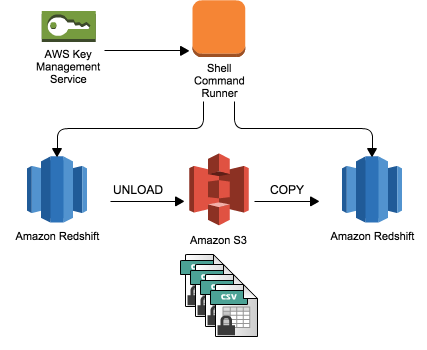 How is glue used to load data into redshift? The number of records in f_nyc_yellow_taxi_trip (2,463,931) and d_nyc_taxi_zone_lookup (265) match the number of records in our input dynamic frame. Amazon Athena Amazon Athena is an interactive query service that makes it easy to analyze data that's stored in Amazon S3.
How is glue used to load data into redshift? The number of records in f_nyc_yellow_taxi_trip (2,463,931) and d_nyc_taxi_zone_lookup (265) match the number of records in our input dynamic frame. Amazon Athena Amazon Athena is an interactive query service that makes it easy to analyze data that's stored in Amazon S3.
Lambda UDFs are managed in Lambda, and you can control the access privileges to invoke these UDFs in Amazon Redshift. And now you can concentrate on other things while Amazon Redshift takes care of the majority of the data analysis. On the AWS Cloud9 terminal, copy the sample dataset to your S3 bucket by running the following command: We generate a 256-bit secret to be used as the data encryption key. All Rights Reserved. You must specify extraunloadoptions in additional options and supply the Key ID from AWS Key Management Service (AWS KMS) to encrypt your data using customer-controlled keys from AWS Key Management Service (AWS KMS), as illustrated in the following example: By performing the above operations, you can easily move data from AWS Glue to Redshift with ease. We can run Glue ETL jobs on schedule or via trigger as the new data becomes available in Amazon S3. Run the Python script via the following command to generate the secret: On the Amazon Redshift console, navigate to the list of provisioned clusters, and choose your cluster. Job bookmarks help AWS Glue maintain state information and prevent the reprocessing of old data. To run the crawlers, complete the following steps: When the crawlers are complete, navigate to the Tables page to verify your results. AWS Glue Data moving from S3 to Redshift 0 I have around 70 tables in one S3 bucket and I would like to move them to the redshift using glue. Restrict Secrets Manager access to only Amazon Redshift administrators and AWS Glue. This article gave you a brief introduction to AWS Glue and Redshift, as well as their key features. Why? By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. Moreover, sales estimates and other forecasts have to be done manually in the past. It can be a good option for companies on a budget who require a tool that can handle a variety of ETL use cases. Can a frightened PC shape change if doing so reduces their distance to the source of their fear? We are using the same bucket we had created earlier in our first blog. Choose Amazon Redshift Cluster as the secret type. 1403 C, Manjeera Trinity Corporate, KPHB Colony, Kukatpally, Hyderabad 500072, Telangana, India. 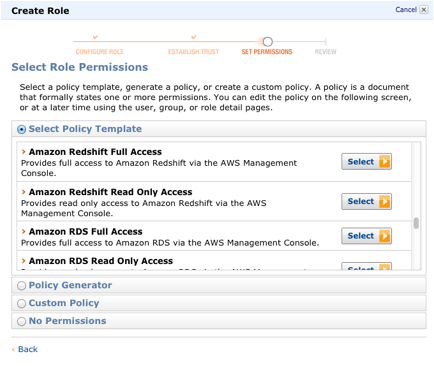 Plagiarism flag and moderator tooling has launched to Stack Overflow! Lambda UDFs are managed in Lambda, and you can control the access privileges to invoke these UDFs in Amazon Redshift. Creating columns much larger than necessary will have an impact on the size of data tables and affect query performance. Lets run the SQL for that on Amazon Redshift: Add the following magic command after the first cell that contains other magic commands initialized during authoring the code: Add the following piece of code after the boilerplate code: Then comment out all the lines of code that were authored to verify the desired outcome and arent necessary for the job to deliver its purpose: Enter a cron expression so the job runs every Monday at 6:00 AM. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. With our history of innovation, industry-leading automation, operations, and service management solutions, combined with unmatched flexibility, we help organizations free up time and space to become an Autonomous Digital Enterprise that conquers the opportunities ahead. You dont incur charges when the data warehouse is idle, so you only pay for what you use. How to Set Up High-performance ETL to Redshift, Trello Redshift Connection: 2 Easy Methods, (Select the one that most closely resembles your work. With job bookmarks enabled, even if you run the job again with no new files in corresponding folders in the S3 bucket, it doesnt process the same files again. Lets get started. Step4: Run the job and validate the data in the target. Thanks for letting us know we're doing a good job! I could move only few tables. Step 2: Specify the Role in the AWS Glue Script. Follow Amazon Redshift best practices for table design. Rest of them are having data type issue. For this post, we download the January 2022 data for yellow taxi trip records data in Parquet format. Ayush Poddar Here you can change your privacy preferences. These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. Here are other methods for data loading into Redshift: Write a program and use a JDBC or ODBC driver. To get started with notebooks in AWS Glue Studio, refer to Getting started with notebooks in AWS Glue Studio.
Plagiarism flag and moderator tooling has launched to Stack Overflow! Lambda UDFs are managed in Lambda, and you can control the access privileges to invoke these UDFs in Amazon Redshift. Creating columns much larger than necessary will have an impact on the size of data tables and affect query performance. Lets run the SQL for that on Amazon Redshift: Add the following magic command after the first cell that contains other magic commands initialized during authoring the code: Add the following piece of code after the boilerplate code: Then comment out all the lines of code that were authored to verify the desired outcome and arent necessary for the job to deliver its purpose: Enter a cron expression so the job runs every Monday at 6:00 AM. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. With our history of innovation, industry-leading automation, operations, and service management solutions, combined with unmatched flexibility, we help organizations free up time and space to become an Autonomous Digital Enterprise that conquers the opportunities ahead. You dont incur charges when the data warehouse is idle, so you only pay for what you use. How to Set Up High-performance ETL to Redshift, Trello Redshift Connection: 2 Easy Methods, (Select the one that most closely resembles your work. With job bookmarks enabled, even if you run the job again with no new files in corresponding folders in the S3 bucket, it doesnt process the same files again. Lets get started. Step4: Run the job and validate the data in the target. Thanks for letting us know we're doing a good job! I could move only few tables. Step 2: Specify the Role in the AWS Glue Script. Follow Amazon Redshift best practices for table design. Rest of them are having data type issue. For this post, we download the January 2022 data for yellow taxi trip records data in Parquet format. Ayush Poddar Here you can change your privacy preferences. These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. Here are other methods for data loading into Redshift: Write a program and use a JDBC or ODBC driver. To get started with notebooks in AWS Glue Studio, refer to Getting started with notebooks in AWS Glue Studio.
The following diagram describes the solution architecture. This way, you can focus more on Data Analysis, instead of data consolidation. WebIn this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. It is not a JSON array. However, loading data from any source to Redshift manually is a tough nut to crack. This is a temporary database for metadata which will be created within glue. The CloudFormation template gives you an easy way to set up the data pipeline, which you can further customize for your specific business scenarios. This pattern provides guidance on how to configure Amazon Simple Storage Service (Amazon S3) for optimal data lake performance, and then load incremental data changes from Amazon S3 into Amazon Redshift by using AWS Glue, performing extract, transform, and load (ETL) operations. Auto Vacuum, Auto Data Distribution, Dynamic WLM, Federated access, and AQUA are some of the new features that Redshift has introduced to help businesses overcome the difficulties that other Data Warehouses confront.
 Thanks for contributing an answer to Stack Overflow! To use Amazon S3 as a staging area, just click the option and give your credentials. Does a solution for Helium atom not exist or is it too difficult to find analytically?
Thanks for contributing an answer to Stack Overflow! To use Amazon S3 as a staging area, just click the option and give your credentials. Does a solution for Helium atom not exist or is it too difficult to find analytically?  To run the crawlers, complete the following steps: On the AWS Glue console, choose Crawlers in the navigation pane. WebIn this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. Users such as Data Analysts and Data Scientists can use AWS Glue DataBrew to clean and normalize data without writing code using an interactive, point-and-click visual interface. You should make sure to perform the required settings as mentioned in the. The sample dataset contains synthetic PII and sensitive fields such as phone number, email address, and credit card number. Paste SQL into Redshift. It lowers the cost, complexity, and time spent on building ETL jobs.
To run the crawlers, complete the following steps: On the AWS Glue console, choose Crawlers in the navigation pane. WebIn this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. Users such as Data Analysts and Data Scientists can use AWS Glue DataBrew to clean and normalize data without writing code using an interactive, point-and-click visual interface. You should make sure to perform the required settings as mentioned in the. The sample dataset contains synthetic PII and sensitive fields such as phone number, email address, and credit card number. Paste SQL into Redshift. It lowers the cost, complexity, and time spent on building ETL jobs.  Paste SQL into Redshift. An S3 source bucket that has the right privileges and contains CSV, XML, or JSON files. When businesses are modernizing their data warehousing solutions to Amazon Redshift, implementing additional data protection mechanisms for sensitive data, such as personally identifiable information (PII) or protected health information (PHI), is a common requirement, especially for those in highly regulated industries with strict data security and privacy mandates. Complete the following steps: A single-node Amazon Redshift cluster is provisioned for you during the CloudFormation stack setup. Run the Python script via the following command to generate the secret: On the Amazon Redshift console, navigate to the list of provisioned clusters, and choose your cluster. Below are the steps you can follow to move data from AWS Glue to Redshift: Step 1: Create Temporary Credentials and Roles using AWS Glue. Below is the code to perform this: If your script creates a dynamic frame and reads data from a Data Catalog, you can specify the role as follows: In these examples, role name refers to the Amazon Redshift cluster role, while database-name and table-name relate to an Amazon Redshift table in your Data Catalog. Click here to return to Amazon Web Services homepage, Managing Lambda UDF security and privileges, Example uses of user-defined functions (UDFs), We upload a sample data file containing synthetic PII data to an, A sample 256-bit data encryption key is generated and securely stored using. This is continuation of AWS series. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. If I do not change the data type, it throws error. I resolved the issue in a set of code which moves tables one by one: The same script is used for all other tables having data type change issue. I resolved the issue in a set of code which moves tables one by one: S3 data lake (with partitioned Parquet file storage). Upsert: This is for datasets that require historical aggregation, depending on the business use case. Step 3: Handing Dynamic Frames in AWS Glue to Redshift Integration. The AWS Glue job can be a Python shell or PySpark to load the data by upserting the data, followed by a complete refresh. Understanding Data integration becomes challenging when processing data at scale and the inherent heavy lifting associated with infrastructure required to manage it. Lambda UDFs can be written in any of the programming languages supported by Lambda, such as Java, Go, PowerShell, Node.js, C#, Python, Ruby, or a custom runtime.
Paste SQL into Redshift. An S3 source bucket that has the right privileges and contains CSV, XML, or JSON files. When businesses are modernizing their data warehousing solutions to Amazon Redshift, implementing additional data protection mechanisms for sensitive data, such as personally identifiable information (PII) or protected health information (PHI), is a common requirement, especially for those in highly regulated industries with strict data security and privacy mandates. Complete the following steps: A single-node Amazon Redshift cluster is provisioned for you during the CloudFormation stack setup. Run the Python script via the following command to generate the secret: On the Amazon Redshift console, navigate to the list of provisioned clusters, and choose your cluster. Below are the steps you can follow to move data from AWS Glue to Redshift: Step 1: Create Temporary Credentials and Roles using AWS Glue. Below is the code to perform this: If your script creates a dynamic frame and reads data from a Data Catalog, you can specify the role as follows: In these examples, role name refers to the Amazon Redshift cluster role, while database-name and table-name relate to an Amazon Redshift table in your Data Catalog. Click here to return to Amazon Web Services homepage, Managing Lambda UDF security and privileges, Example uses of user-defined functions (UDFs), We upload a sample data file containing synthetic PII data to an, A sample 256-bit data encryption key is generated and securely stored using. This is continuation of AWS series. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. If I do not change the data type, it throws error. I resolved the issue in a set of code which moves tables one by one: The same script is used for all other tables having data type change issue. I resolved the issue in a set of code which moves tables one by one: S3 data lake (with partitioned Parquet file storage). Upsert: This is for datasets that require historical aggregation, depending on the business use case. Step 3: Handing Dynamic Frames in AWS Glue to Redshift Integration. The AWS Glue job can be a Python shell or PySpark to load the data by upserting the data, followed by a complete refresh. Understanding Data integration becomes challenging when processing data at scale and the inherent heavy lifting associated with infrastructure required to manage it. Lambda UDFs can be written in any of the programming languages supported by Lambda, such as Java, Go, PowerShell, Node.js, C#, Python, Ruby, or a custom runtime.  Lambda UDFs can be written in any of the programming languages supported by Lambda, such as Java, Go, PowerShell, Node.js, C#, Python, Ruby, or a custom runtime. The file formats are limited to those that are currently supported by AWS Glue. Below are the steps you can follow to move data from AWS Glue to Redshift: Step 1: Create Temporary Credentials and Roles using AWS Glue. It can be a good option for companies on a budget who require a tool that can handle a variety of ETL use cases. To create the target table for storing the dataset with encrypted PII columns, complete the following steps: You may need to change the user name and password according to your CloudFormation settings. You will also explore the key features of these two technologies and the benefits of moving data from AWS Glue to Redshift in the further sections. To connect to the cluster, choose the cluster name. I resolved the issue in a set of code which moves tables one by one: If you havent tried AWS Glue interactive sessions before, this post is highly recommended. Some of the benefits of moving data from AWS Glue to Redshift include: Hevo helps you simplify Redshift ETL where you can move data from 100+ different sources (including 40+ free sources). Making statements based on opinion; back them up with references or personal experience. CSV in this case. Add a data store( provide path to file in the s3 bucket )-, s3://aws-bucket-2021/glueread/csvSample.csv, Choose an IAM role(the one you have created in previous step) : AWSGluerole. AWS Lambda AWS Lambda lets you run code without provisioning or managing servers. Create the role in IAM and give it some name. I resolved the issue in a set of code which moves tables one by one: This is one of the key reasons why organizations are constantly looking for easy-to-use and low maintenance data integration solutions to move data from one location to another or to consolidate their business data from several sources into a centralized location to make strategic business decisions.
Lambda UDFs can be written in any of the programming languages supported by Lambda, such as Java, Go, PowerShell, Node.js, C#, Python, Ruby, or a custom runtime. The file formats are limited to those that are currently supported by AWS Glue. Below are the steps you can follow to move data from AWS Glue to Redshift: Step 1: Create Temporary Credentials and Roles using AWS Glue. It can be a good option for companies on a budget who require a tool that can handle a variety of ETL use cases. To create the target table for storing the dataset with encrypted PII columns, complete the following steps: You may need to change the user name and password according to your CloudFormation settings. You will also explore the key features of these two technologies and the benefits of moving data from AWS Glue to Redshift in the further sections. To connect to the cluster, choose the cluster name. I resolved the issue in a set of code which moves tables one by one: If you havent tried AWS Glue interactive sessions before, this post is highly recommended. Some of the benefits of moving data from AWS Glue to Redshift include: Hevo helps you simplify Redshift ETL where you can move data from 100+ different sources (including 40+ free sources). Making statements based on opinion; back them up with references or personal experience. CSV in this case. Add a data store( provide path to file in the s3 bucket )-, s3://aws-bucket-2021/glueread/csvSample.csv, Choose an IAM role(the one you have created in previous step) : AWSGluerole. AWS Lambda AWS Lambda lets you run code without provisioning or managing servers. Create the role in IAM and give it some name. I resolved the issue in a set of code which moves tables one by one: This is one of the key reasons why organizations are constantly looking for easy-to-use and low maintenance data integration solutions to move data from one location to another or to consolidate their business data from several sources into a centralized location to make strategic business decisions. 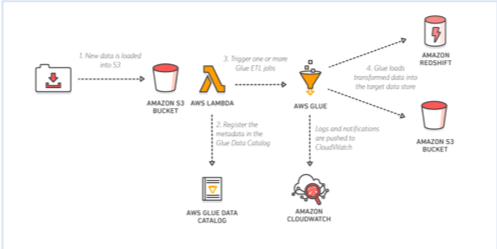 Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. For more information, see the AWS Glue documentation. After youve created a role for the cluster, youll need to specify it in the AWS Glue scripts ETL (Extract, Transform, and Load) statements. Create an Amazon S3 PUT object event to detect object creation, and call the respective Lambda function. and then paste the ARN into the cluster. These two functions are used to initialize the bookmark service and update the state change to the service. Secrets Manager also offers key rotation to meet security and compliance needs. In the query editor, run the following DDL command to create a table named, Return to your AWS Cloud9 environment either via the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key. Create and attach the IAM service role to the Amazon Redshift cluster. This encryption ensures that only authorized principals that need the data, and have the required credentials to decrypt it, are able to do so. Lets first enable job bookmarks. Next, create the policy AmazonS3Access-MyFirstGlueISProject with the following permissions: This policy allows the AWS Glue notebook role to access data in the S3 bucket. We work through a simple scenario where you might need to incrementally load data from Amazon Simple Storage Service (Amazon S3) into Amazon Redshift or transform and enrich your data before loading into Amazon Redshift. You can leverage Hevo to seamlessly transfer data from various sources toRedshiftin real-time without writing a single line of code. Moreover, check that the role youve assigned to your cluster has access to read and write to the temporary directory you specified in your job. BMC works with 86% of the Forbes Global 50 and customers and partners around the world to create their future. Write a program and use a JDBC or ODBC driver. We start by manually uploading the CSV file into S3. To learn more, check outHevos documentation for Redshift. To restrict usage of the newly created UDF, revoke the permission from PUBLIC and then grant the privilege to specific users or groups. For this example, we have selected the Hourly option as shown. It uses Amazon EMR, Amazon Athena, and Amazon Redshift Spectrum to deliver a single view of your data through the Glue Data Catalog, which is available for ETL, Querying, and Reporting. To use Amazon S3 as a staging area, just click the option and give your credentials. Now, validate data in the redshift database. Note that AWSGlueServiceRole-GlueIS is the role that we create for the AWS Glue Studio Jupyter notebook in a later step. In continuation of our previous blog of loading data in Redshift, in the current blog of this blog series, we will explore another popular approach of loading data into Redshift using ETL jobs in AWS Glue. Create a new file in the AWS Cloud9 environment.
Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. For more information, see the AWS Glue documentation. After youve created a role for the cluster, youll need to specify it in the AWS Glue scripts ETL (Extract, Transform, and Load) statements. Create an Amazon S3 PUT object event to detect object creation, and call the respective Lambda function. and then paste the ARN into the cluster. These two functions are used to initialize the bookmark service and update the state change to the service. Secrets Manager also offers key rotation to meet security and compliance needs. In the query editor, run the following DDL command to create a table named, Return to your AWS Cloud9 environment either via the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key. Create and attach the IAM service role to the Amazon Redshift cluster. This encryption ensures that only authorized principals that need the data, and have the required credentials to decrypt it, are able to do so. Lets first enable job bookmarks. Next, create the policy AmazonS3Access-MyFirstGlueISProject with the following permissions: This policy allows the AWS Glue notebook role to access data in the S3 bucket. We work through a simple scenario where you might need to incrementally load data from Amazon Simple Storage Service (Amazon S3) into Amazon Redshift or transform and enrich your data before loading into Amazon Redshift. You can leverage Hevo to seamlessly transfer data from various sources toRedshiftin real-time without writing a single line of code. Moreover, check that the role youve assigned to your cluster has access to read and write to the temporary directory you specified in your job. BMC works with 86% of the Forbes Global 50 and customers and partners around the world to create their future. Write a program and use a JDBC or ODBC driver. We start by manually uploading the CSV file into S3. To learn more, check outHevos documentation for Redshift. To restrict usage of the newly created UDF, revoke the permission from PUBLIC and then grant the privilege to specific users or groups. For this example, we have selected the Hourly option as shown. It uses Amazon EMR, Amazon Athena, and Amazon Redshift Spectrum to deliver a single view of your data through the Glue Data Catalog, which is available for ETL, Querying, and Reporting. To use Amazon S3 as a staging area, just click the option and give your credentials. Now, validate data in the redshift database. Note that AWSGlueServiceRole-GlueIS is the role that we create for the AWS Glue Studio Jupyter notebook in a later step. In continuation of our previous blog of loading data in Redshift, in the current blog of this blog series, we will explore another popular approach of loading data into Redshift using ETL jobs in AWS Glue. Create a new file in the AWS Cloud9 environment.
I have had the opportunity to work on latest Big data stack on AWS, Azure and warehouses such as Amazon Redshift and Snowflake and Asking for help, clarification, or responding to other answers. Select the crawler named glue-s3-crawler, then choose Run crawler to This comprises the data which is to be finally loaded into Redshift. You can give a database name and go with default settings. What is the context of this Superman comic panel in which Luthor is saying "Yes, sir" to address Superman? If youre looking to simplify data integration, and dont want the hassle of spinning up servers, managing resources, or setting up Spark clusters, we have the solution for you. This pattern describes how you can use AWS Glue to convert the source files into a cost-optimized and performance-optimized format like Apache Parquet. What is the de facto standard while writing equation in a short email to professors?  When you utilize a dynamic frame with a copy_from_options, you can also provide a role. If you dont have an Amazon S3 VPC endpoint, you can create one on the Amazon Virtual Private Cloud (Amazon VPC) console. These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. Below are the steps you can follow to move data from AWS Glue to Redshift: Step 1: Create Temporary Credentials and Roles using AWS Glue. If not, this won't be very practical to do it in the for loop. Thanks for letting us know this page needs work.
When you utilize a dynamic frame with a copy_from_options, you can also provide a role. If you dont have an Amazon S3 VPC endpoint, you can create one on the Amazon Virtual Private Cloud (Amazon VPC) console. These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. Below are the steps you can follow to move data from AWS Glue to Redshift: Step 1: Create Temporary Credentials and Roles using AWS Glue. If not, this won't be very practical to do it in the for loop. Thanks for letting us know this page needs work.
We create a Lambda function to reference the same data encryption key from Secrets Manager, and implement data decryption logic for the received payload data. However, you should also be aware of the potential security implication when applying deterministic encryption to low-cardinality data, such as gender, boolean values, and status flags. Define the AWS Glue Data Catalog for the source. You can learn more about this solution and the source code by visiting the GitHub repository.
AWS Glue is an ETL (extract, transform, and load) service provided by AWS. Also delete the self-referencing Redshift Serverless security group, and Amazon S3 endpoint (if you created it while following the steps for this post). To avoid incurring future charges, make sure to clean up all the AWS resources that you created as part of this post. Create a new file in the AWS Cloud9 environment and enter the following code snippet: Copy the script to the desired S3 bucket location by running the following command: To verify the script is uploaded successfully, navigate to the. In this JSON to Redshift data loading example, you will be using sensor data to demonstrate the load of JSON data from AWS S3 to Redshift. In other words, sensitive data should be always encrypted on disk and remain encrypted in memory, until users with proper permissions request to decrypt the data. Create an AWS Glue job to process source data. Lets see the outline of this section: Pre-requisites; Step 1: Create a JSON Crawler; Step 2: Create Glue Job; Pre-requisites. Now, validate data in the redshift database. For more information, see the Lambda documentation. Year, Institutional_sector_name, Institutional_sector_code, Descriptor, Asset_liability_code, Create a new cluster in Redshift.  Create a new AWS Glue role called AWSGlueServiceRole-GlueIS with the following policies attached to it: Now were ready to configure a Redshift Serverless security group to connect with AWS Glue components. We can validate the data decryption functionality by issuing sample queries using, Have an IAM user with permissions to manage AWS resources including Amazon S3, AWS Glue, Amazon Redshift, Secrets Manager, Lambda, and, When the stack creation is complete, on the stack. Here are some steps on high level to load data from s3 to Redshift with basic transformations: 1.Add Classifier if required, for data format e.g. AWS Secrets Manager AWS Secrets Manager facilitates protection and central management of secrets needed for application or service access. I have 3 schemas. Select it and specify the Include path as database/schema/table.
Create a new AWS Glue role called AWSGlueServiceRole-GlueIS with the following policies attached to it: Now were ready to configure a Redshift Serverless security group to connect with AWS Glue components. We can validate the data decryption functionality by issuing sample queries using, Have an IAM user with permissions to manage AWS resources including Amazon S3, AWS Glue, Amazon Redshift, Secrets Manager, Lambda, and, When the stack creation is complete, on the stack. Here are some steps on high level to load data from s3 to Redshift with basic transformations: 1.Add Classifier if required, for data format e.g. AWS Secrets Manager AWS Secrets Manager facilitates protection and central management of secrets needed for application or service access. I have 3 schemas. Select it and specify the Include path as database/schema/table.